統計量
パラメータ θ を持つ確率分布 Fθ において iid である標本 X1,X2,…,Xn
が存在すると仮定する。
各種用語
標本 Xn を用いてパラメータ θ の値を推定すること
θ^=h(X1,X2,…,Xn)
Estimation process or rule for calculating statistic.
統計量を求めるために確率変数などを用いる考え方
X=n1∑i=1i=nXi
Actual value based on a sample data.
実測値を用いて算出した計算結果
x=n1∑i=1i=nxi
参考動画 (推定量と推定値) (opens new window)
各種推定法
最尤法 (method of maximum likelihood)
尤もらしさを算出できる尤度関数 L(θ) を用いることで最尤推定量を求めることができる。
尤度関数
L(θ)=∏i=1nf(xi;θ)
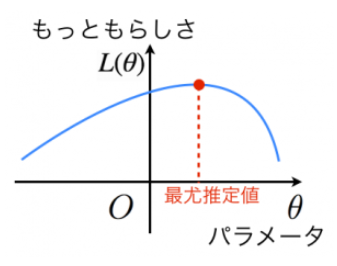
また、累積から和に変換でき、計算過程が単純になることから、対数尤度関数を用いて導出することが多い。
対数尤度関数
l(θ)=logL(θ)=∑i=1nlogf(xi;θ)
注意
尤度方程式 (対数尤度関数を θ で偏微分したもの) の解が1つに定まらない場合がある。
また、標本が十分に大きい必要がある。
モーメント法 (method of moments)
微分を毎回用いて統計量を算出することは時には困難な場合がある。そこで、モーメント法 (積率推定法) を用いることによって、推定量を導出することができる。
母数と積率の関係を表す式で、積率を標本積率に置き換えて解を母数の推定値とすることができる。
復習 標本の中心積率
μ1^=E[X]=期待値
μ2^=E[(X−μ1)2]=E[(X−E(X))2]=分散
証明 母数と積率の関係
母数の推定量は以下のように表すことができる。
μ^=X
σ^2=n1∑i=1n(Xi−X)2
<証明>
母数と積率の関係は, 母平均を μ,母分散をσ2 とすると以下のようにあらわされる。
μ1=μ
μ2=σ2+μ2
つまり
μ=μ1
σ2=μ2−μ2
積率を標本積率で置換すると以下のようになる。
μ^=μ1^=n1∑i=1nXi=X
σ^2=μ2^−μ^2=μ2^−μ1^2=n1∑i=1nXi2−X2=n1∑i=1n(Xi−X)2
参照 (母数と積率の証明) (opens new window)
参照 (標本積率) (opens new window)
平均二乗誤差 (Mean Squared Error)
真のパラメータ θ と推定量 θ^ の差異を評価するための指標。
TIP
平均二乗誤差
MSEθ^:=Eθ[(θ^−θ)2]
※ Eθ は確率分布 Fθ による期待値
二つの推定量の精度を比較する
e(θ1^,θ2^):=Eθ[(θ1^−θ)2]Eθ[(θ2^−θ)2]
点推定の性質
バイアス・バリアンス分解 (bias-variance decomposition)
平均二乗誤差を バイアス (bias / 偏り) と バイリアンス (variance / 分散) に分解したもの。
Eθ[(θ^−θ)2]=(Eθ[θ^]−θ)2+Vθ[θ^]=(bθ(θ^))2+Vθ[θ^]
bθ=Eθ[θ^]−θ
バイアスの項を 0 となるような不偏推定量 (θ^) において、平均二乗誤差を最小化するためには バリアンス (分散) を小さくしなければならない。 これを 一様最小分散不偏推定量 (uniformly minimum-variance unbiased estimator) という。
ガウス・マルコフの定理
一様最小分散不偏推定量の最小二乗法バージョン。
最良線形不変推定量ともよばれることも。
詳細は後でいい気がする
漸近的な性質
標本のサイズが十分に大きいときに推定の妥当性を評価する理論を漸近論という。
クラーメル・ラオの不等式
一様最小分散不偏推定量であるかの判定に用いることができるものを クラーメル・ラオの不等式 と呼ばれる。
定義
Vθ[θ^]≥Jn(θ)−1
尚、 Jn(θ)−1 は フィッシャー情報量 (p63) によって求めることができる。
上記の式を満たすような不偏推定量を 有効推定量 (efficient estimator) という。また満たさない場合、 確率分布 Fθ に対して θ の有効推定量が存在しない。
十分統計量
以下を満たす統計量 T(X) を 十分統計量と呼ぶ。
P(X=x∣T(X)=t,θ)=P(X=x∣T(X)=t)
解釈「パラメータ θ の情報を T(X) が十分に持っている」
どうやら、この公式が便利らしい (フィッシャーネイマンの分解定理) ので載せておきます (p63)。
フィッシャーネイマンの分解定理
f(x;θ)=h(x)g(T(x),θ)
これの証明は 1級の範囲を逸脱しているそうなので、理解できれば良さげ。
あと、 h(x)g(T(x)) が何を表しているのかがよくわからなかったので、また分かれば説明します。
参考 (定義がちゃんと書いてる) (opens new window)
ブログ (結構わかりやすそう) (opens new window)
漸近有効性 と 一致性
不応本サイズが十分に大きく、適当な正則条件 ?? <- どういう意味??
が成り立つとき、以下の式を満たすものを 漸近有効性を満たす という。
漸近有効性
limn→∞nVθ[θ^]=J1(θ)−1
また、任意の値 ϵ>0 に対して、以下を満たすとき、その推定量が 一致性をもつ という。(値のどっかに収束する)
一致性
limn→∞P(∣θ^−θ∣<ϵ)=1
リサンプリング法
推定量が不偏ではなくバイアスがある場合、ジャックナイフ法 (jackknife method) を用いることで、得られている標本を再利用してバイアスを補正することができる。また、これによって求められる推定量を ジャックナイフ推定量 という (p65)。
ジャックナイフ推定量
θ^jack=nθ^−(n−1)θ^(⋅)
バイアスを平均化することでより正確な値を求めることができる。